บทความนี้เป็นการใช้งานคลังไลบรารี Pandas ของภาษาไพธอนโดยใช้บอร์ด Raspberry Pi 3 B+ เป็นอุปกรณ์ทำงาน โดยสามารถนำไปประยุกต์ใช้งานกับไพธอนของระบบปฏิบัติการ Windows, macOS หรือ Linux ได้ ซึ่งบทความนี้จะแบ่งเป็นหลายตอนเหมือนกับคลังไลบรารี ulab ที่ผ่านมา โดยในบทความตอนที่ 1 กล่าวถึงคุณสมัติของ Pandas, การติดตั้ง และโครงสร้างข้อมูลของ Pandas

Pandas
Pandas ถูกพัฒนาต่อเนื่องมาตั้งแต่ปี ค.ศ.2008 [1] เพื่อเป็นคลังไลบรารีแบบเปิดเผยโค้ด (Open Source) ที่ใช้ลิขสิทธิ์แบบ BSD ซึ่งเป็นเครื่องมือสำหรับทำงานเกี่ยวกับโครงสร้างข้อมูลและการวิเคราะห์ข้อมูล ทำให้เป็นที่นิยมใช้สำหรับงานประยุกต์เกี่ยวกับการเงิน เศรษฐศาสตร์ สถิติ และการวิเคราะห์ข้อมูล เป็นต้น โดยวิศัยทัศน์ของ Pandas คือ ให้ทุกคนเข้าถึงได้ อิสระในการใช้และปรับแต่ง ยืดหยุ่น ทรงพลัง ใช้ง่าย และทำงานได้เร็ว จุดเด่นของไลบรารีเป็นดังนี้
- มี DataFrame ที่ทำงานได้รวดเร็วสำหรับการบริหารจัดการกับข้อมูลและเข้าถึงได้ด้วยการอ้างอิงตำแหน่งของข้อมูล (indexing)
- มีเครื่องมือในการอ่านและเขียนข้อมูลในหน่วยความจำกับรูปแบบข้อมูลภายนอกที่เป็น CSV,ไฟล์ข้อความ, ไฟล์ Excel ของ Microsoft, ไฟล์ SQL ของระบบจัดการฐานข้อมูล และรูปแบบไฟล์ HDF5
- มีระบบ Data Alignment และตัวจัดการข้อมูลผิดพลาด (Missing Data)
- ยืดหยุ่นในการปรับเปลี่ยนขนาด (reshape) และไพวอต (Pivot) ของก้อนข้อมูล (Data sets)
- สามารถทำการเลื่อนข้อมูล (Slicing), xxx (fancy indexing) และ xxx (subsetting) กับก้อนข้อมูลขนาดใหญ่
- สามารถเพิ่มและลบคอลัมน์ได้ตามโครงสร้างข้อมูลที่นำมาใช้
- รองรับการจัดกลุ่มและแปลงก้อนข้อมูล
- ประสิทธิภาพสูงในการรวม (join) และต่อเชื่อม (merge) ก้อนข้อมูลขนาดใหญ่
- ใช้การอ้างอิงในแบบระดับชั้น (Hierarchical axis indexing) ทำให้รองรับการทำงานกับข้อมูลแบบหลายมิติ
- มีฟังชันทำงานด้านอนุกรมเวลา (Time series-functionality) ได้แก่
- date range generation และ frequency conversion
- การย้ายวินโดว์ทางสถิติ
- การเลื่อนวันที่
- สร้างโดเมนเวลาตามที่ต้องการ
- เชื่อมอนุกรมเวลาโดยไม่สูญเสียข้อมูล
- ปรับแต่งประสิทธิภาพการทำงานเพื่อให้เรียกใช้ผ่าน Cython
ติดตั้ง Pandas
การติดตั้ง Pandas สามารถทำผ่าน pip ด้วยคำสั่งดังนี้
pip3 install pandas
สำหรับการอัพเกรดใช้คำสั่งรูปแบบต่อไปนี้
pip3 install –upgrade pandas
หมายเหตุ
กรณีที่ใช้กับระบบปฏิบัติการ Windows หรือ Linux รุ่นใหม่ที่ยกเลิกการติดตั้งไลบรารีและเครื่องมือของไพธอนรุ่น 2 (เช่น Ubuntu 20.04 เป็นต้นมา) ใช้คำสั่ง pip แทน pip3
โครงสร้างข้อมูล
โครงสร้างข้อมุลในการจัดเก็บข้อมูลของ Pandas มี 3 ประเภท คือ
- Series เป็นโครงสร้างข้อมูลแถวลำดับแบบ 1 มิติ มีแกนเดียว คือ axis 0
- DataFrame เป็นโครงสร้างข้อมูลแถวลำดับ 2 มิติ มีข้อมูล 2 แกน (axis) คือ axis 0 หรือแถว และ 1 หรือคอลัมน์ โดยแต่ละคอลัมน์จะต้องเป็นข้อมูลประเภทเดียวกัน
- Panel เป็นโครงสร้างข้อมูลแถวลำดับ 3 มิติ มีข้อมูล 3 แกน (axis) คือ axis 0, 1 และ 2 สำหรับอ้างอิงค่าแถว,คอลัมน์ และระดับความลึก เป็นการนำข้อมูลแบบ DataFrame หลายชุดมาซ้อนกัน เช่น มี DataFrame ยอดขายแต่ละเดือน เมื่อนำมาเป็น Panel คือ มี DataFrame ของเดือน ม.ค. ถึง ธ.ค. มาซ้อนกันในแกนความลึก
ตัวอย่างการโหลด CSV มาเป็น DataFrame
ตัวอย่างโปรแกรมต่อไปนี้เป็นการโหลดไฟล์ csv ชื่อ data-travel-phetchaburi-2018.csv ซึ่งตัวอย่างของไฟล์เป็นดังภาพที่ 1
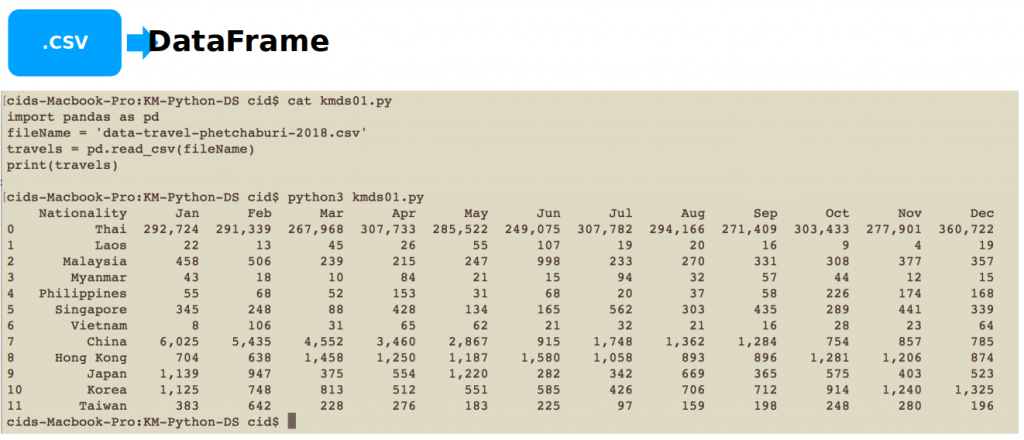
import pandas as pd
fileName = 'data-travel-phetchaburi-2018.csv'
travels = pd.read_csv(fileName)
print(travels)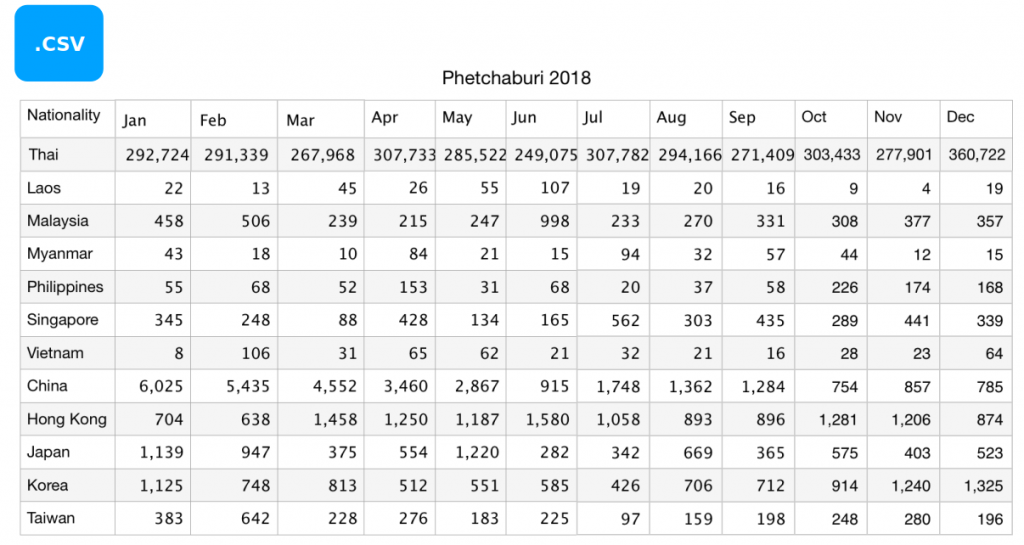
เมื่อรันโปรแกรม kmds01.py จะได้ผลลัพธ์ดังภาพที่ 2
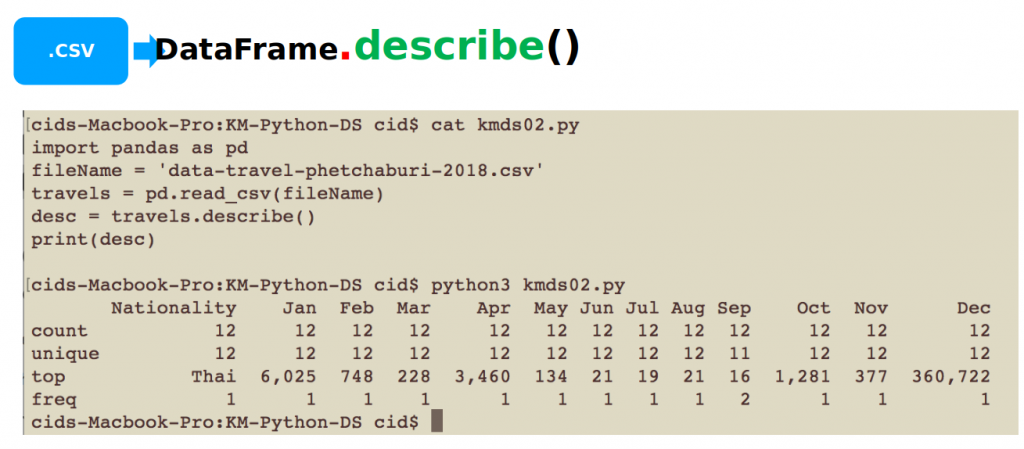
การ describe
การสั่งให้มีการ describe ข้อมูลภายใน DataFrame ทำได้โดยเรียกใช้เมธอด describe() ดังตัวอย่างโปรแกรม kmds02.py
import pandas as pd
fileName = 'data-travel-phetchaburi-2018.csv'
travels = pd.read_csv(fileName)
desc = travels.describe()
print(desc)
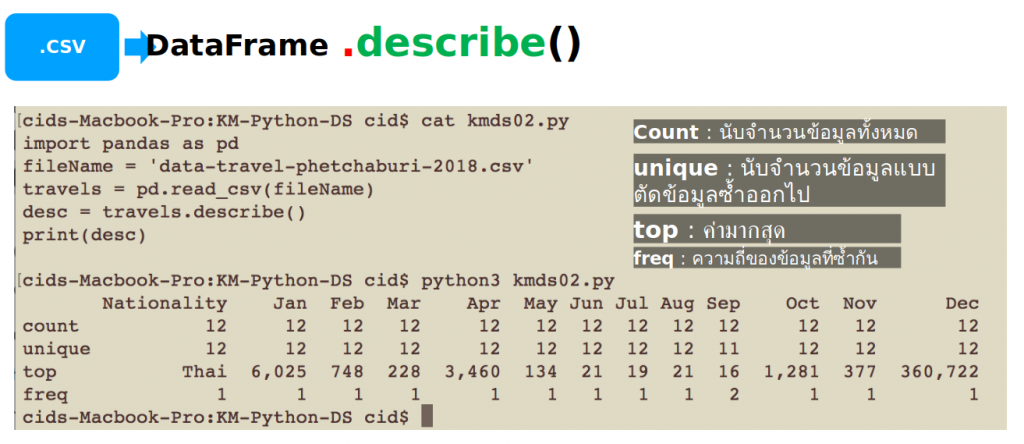
ตัวอย่างของผลลัพธ์จากการทำงานของ kmds02.py เป็นดังภาพที่ 3 และ 4 ซึ่งจะได้การประเมินผลเกี่ยวกับ count, unique, top และ freq
ตัวอย่าง info/shape/head/tail/sample และการบันทึก
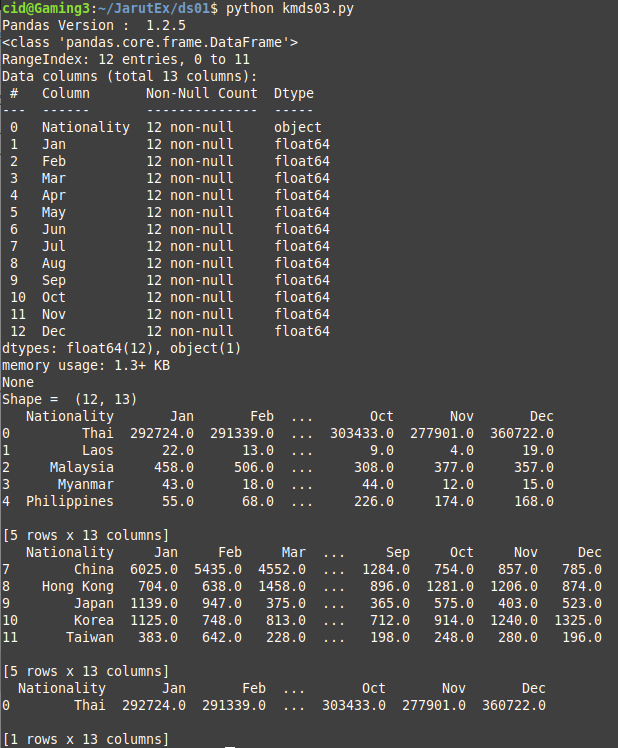
ตัวอย่างโปรแกรม kmds03.py เป็นการโหลดข้อมูลจาก csv หลังจากนั้นแสดงรุ่นของ pandas แสดง info ของ DataFrame, แสดงขนาดของตาราง (shape), แสดงข้อมูลส่วนหัว ส่วนหาง ตัวอย่าง และดำเนินการบันทึก DataFrame ลงไฟล์ csv และ json
import pandas as pd
fileName = 'data-travel-phetchaburi-2018.csv'
travels = pd.read_csv(fileName)
print("Pandas Version : ", pd.__version__)
print(travels.info())
print('Shape = ',travels.shape)
print(travels.head())
print(travels.tail())
print(travels.sample())
travels.to_csv('data-travel-result.csv')
travels.to_json('data-travel-result.json')ตัวอย่างของการทำงาน kmds03.py เป็นดังภาพที่ 5
ตัวอย่างการ sum/min/max/mean
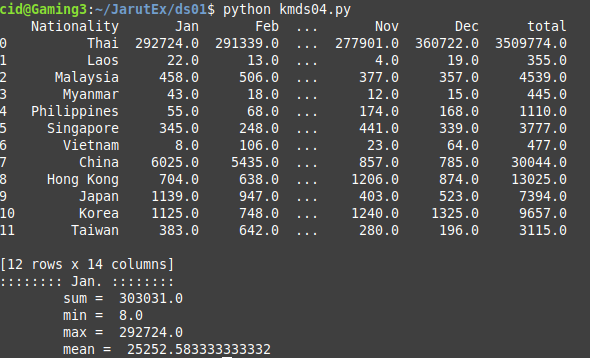
ตัวอย่างโปรแกรม kmds04.py เป็นการประมวลผลข้อมูลใน DataFrame เพื่อหาผลรวม ค่าน้อยที่สุด ค่ามากที่สุด และค่าเฉลี่ย โดยเลือกประมวลผลเฉพาะเดือน Jan
import pandas as pd
fileName = 'data-travel-phetchaburi-2018.csv'
travels = pd.read_csv(fileName)
travels['total'] = travels.sum(axis=1)
print(travels)
Jan = travels['Jan']
print(":::::::: Jan. ::::::::")
print('\tsum = ',Jan.sum())
print('\tmin = ',Jan.min())
print('\tmax = ',Jan.max())
print('\tmean = ',Jan.mean())ตัวอย่างของผลลัพธ์การทำงานจาก kmds04.py เป็นดังภาพที่ 6
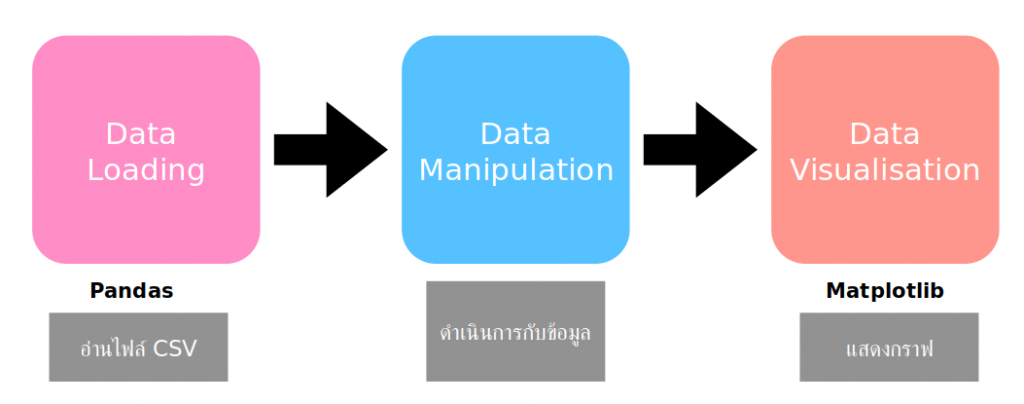
เมื่อได้ข้อมูลและนำมาประมวลผลข้อมูลซึ่งมีหลากหลายวิธีที่จะขอกล่าวต่อไปในบทความถัด ๆ ไป ตอนนี้สรุปได้ว่าการทำ Data Science มีขั้นตอนพื้นฐานเบื้องต้น 3 ขั้นตอนดังภาพที่ 7 คือ นำข้อมูลเข้าผ่านทาง Pandas หลังจากนั้นดำเนินการกับข้อมูล และสุดท้ายแสดงข้อมูลในรูปแบบของกราฟผ่าน Matplotlib
จากตัวอย่างการอ่านข้อมูลมาเก็บใน DataFrame หลังจากนั้น describe() และประมวลผลข้อมูลกันไปบ้างแล้วนั้น ผู้อ่านค้นพบอะไรน่าสนใจจากข้อมูลกันบ้างครับ
สรุป
บทความนี้ได้บอกถึงคุณสมบัติและการติดตั้ง Pandas ซึ่งเป็นคลังไลบรารีที่ถูกใช้มากในงานด้าน AI พร้อมทั้งได้กล่าวถึงโครงสร้างการจัดเก็บข้อมูลของ Pandas ที่ชื่อ Series, DataFrame และ Panel โดยเริ่มต้นการใช้งานด้วยการอ่านข้อมูลจากไฟล์ csv ที่เกี่ยวข้องกับสถิติการท่องเที่ยวในจังหวัดเพชรบุรีปี ค.ศ. 2018 เมื่อนำมาผ่านเมธอด describe() จึงได้ข้อมูลสรุปที่น่าสนใจมากขึ้นเกี่ยวกับการ count, unique, top และ freq ส่วนในบทความตอนถัดไปจะกล่าวถึงเรื่องที่เกี่ยวข้องต่อไป สุดท้ายนี้หวังว่าบทความนี้คงมีประโยชน์บ้างไม่มากก็น้อย และขอให้สนุกกับการเขียนโปรแกรมครับ
อ้างอิง
(C) 2020-2021, โดย อ.ดนัย เจษฎาฐิติกุล/อ.จารุต บุศราทิจ
ปรับปรุงเมื่อ 2020-11-30, 2021-06-29
ปรับปรุงเมื่อ 2021-08-26